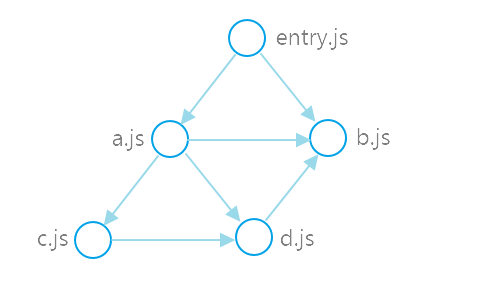
It is not always obvious where import x from 'module' should look to find the file behind module, it depends on module resolution algorithms, which are specific for module bundlers, module syntax specs, etc.. deps-walker uses resolve package, which implements NodeJS module resolution behavior. You may configure NodeJS resolve via available options:
Welcome to my personal dotfiles repository, tailored for the 🐟 Fish shell. These configurations are designed to create a baseline for my development environment, integrating seamlessly with VSCode, Starship, tmux, etc.
Key Features
Prompt Customization with ⭐️🚀 Starship: A sleek, informative command-line interface built in Rust.
Effortless Dotfile Management: Uses chezmoi for a streamlined process to update, install, and configure my environment with a simple one-line command.
Intelligent OS Detection: Automatically installs OS-specific packages, ensuring compatibility and ease of setup.
User-Guided Installation Script: Tailored setup with interactive prompts to select only the tools I need.
Enhanced File Listing with eza: A more colorful and user-friendly ls command.
Optimized Tmux Configuration: Benefit from a powerful Tmux setup by gpakosz, enhancing your terminal multiplexer experience.
Getting Started
Compatibility
Note: This setup is currently optimized for macOS and Debian-based Linux distributions.
Installation
To install, choose one of the following methods and execute the command in my terminal:
Curl:
sh -c "$(curl -fsLS get.chezmoi.io)" -- init --apply mmena1
Wget:
sh -c "$(wget -qO- get.chezmoi.io)" -- init --apply mmena1
Keep my environment fresh and up-to-date with a simple command:
chezmoi update
This will fetch and apply the latest changes from the repository, ensuring my setup remains optimal.
Under the Hood
Custom Fish Scripts
Leveraging the best of oh-my-zsh, I’ve crafted custom Fish scripts, including git and eza abbreviations, enriching my shell without the need for plugins.
Chezmoi: The Backbone
At the heart of my dotfile management is Chezmoi, a robust tool offering templating features to dynamically adapt scripts across various systems, alongside the capability to preview and verify scripts before execution.
Modular Task Management
A task-based approach is used for managing the setup and configuration of my development environment. Instead of running a monolithic script, the setup process is broken down into discrete tasks that can be individually registered, managed, and executed.
Key features of the task management system:
Task Registration: Each setup component is registered as a task with a name, description, list of dependencies, and execution function.
Dependency Resolution: Tasks specify their dependencies, ensuring they’re executed in the correct order. For example, package installation requires Homebrew to be installed first (only for macOS).
Interactive Execution: Before each task runs, I’m prompted to confirm, letting me customize my setup process.
Error Handling: If a task fails, I can choose to continue with the remaining tasks or abort the setup.
Modular Implementation: Setup components are organized into modules (package management, shell configuration, development tools, etc.) that can be maintained independently.
This approach makes the setup process more maintainable, flexible, and user-friendly. New tasks can be added without modifying existing code, and dependencies are automatically resolved to ensure a smooth setup experience.
Iforgor is a customisable and easy to use command line tool to manage code samples.
It’s a good way to quickly get your hand on syntax you dont remember right from your terminal without wasting time looking on the internet.
Installation
Method :
Creates symlinks of iforgor.py and the snippets folder to /usr/local/bin. So that it can be run from anywhere on the terminal.
Requirements :
Python.
Git.
The colorama python module.
Step by step procedure :
Open a terminal and cd into the directory you want to install the program into.
Run “./setup.sh” as root (it has to be run as root since it needs to create files in /usr/local/bin), add the ungit argument to remove github related files and folders like the readme and license.
Run “iforgor -h”
If it works, the install was successful.
You can then delete setup.sh
Uninstall:
To uninstall, simply delete the ‘iforgor’ and ‘snippets’ symlinks in /usr/local/bin.
Then delete the iforgor folder.
Iforgor 101
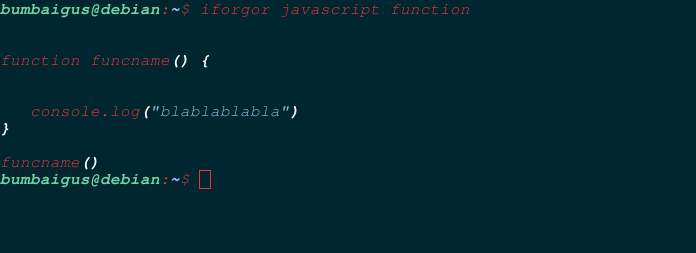
To display a piece of code, run the following.
iforgor LANGUAGE SNIPPET
The language argument represents a folder in the “snippets” directory.
You can add any language you want by creating a folder in it.
The snippet argument represents a *.txt file in the specified language directory that containd the code sample you want to display.
You can add any code sample by creating a *.txt in a desired language folder.
So if you want to add a function sample for the, lets say Rust language for example.
You will have to create a directory named “rust” in the snippets folder.
And create a function.txt file in the rust folder with the code you want inside.
You can then print it out by running iforgor rust function
Pro tips:
Languages and snippets are case insensitive. So you can run ‘iforgor lAnGuAgE sNiPpeT’.
You dont need to do the setup process, but its required if you want to be able to run iforgor easily from anywhere.
There are default snippets yes, but iforgor is designed to be customized, dont hesitate to add your own custom snippets and languages.
Screenshots:
Compatibility
Linux
This should work on pretty much any linux distro, but i can make mistakes, so dont hesitate opening an issue if you face problems.
Iforgor was tested on:
Debian 11 : Working
Void Linux : Working
Arch Linux : Working
BSDs and other unix based operating systems.
Those are less certain to work, but you can still give it a try.
Tested on:
FreeBSD : Working
OpenBSD : Working
Want to contribute ?
Sure. All help is accepted.
The code is very commented if you want to take a look at it.
PLEASE dont forget to star the project if you find it interesting, it helps out a ton.
A high-level real-time audio playback, generation and recording library based on miniaudio. The library offers basic functionality and quite low latency. Supports MP3, WAV and FLAC formats.
Platform support
Platform
Tested
Supposed to work
Unsupported
Android
SDK 31, 19
SDK 16+
SDK 15-
iOS
None
Unknown
Unknown
Windows
11, 7 (x64)
Vista+
XP-
macOS
None
Unknown
Unknown
Linux
Fedora 39-40, Mint 22
Any
None
Web
Chrome 93+, Firefox 79+, Safari 16+
Browsers with an AudioWorklet support
Browsers without an AudioWorklet support
Migration
There was some pretty major changes in 2.0.0 version, see the migration guide down below.
Getting started on the web
While the main script is quite large, there is a loader script provided. Include it in the web/index.html file like this
It is highly recommended NOT to make the script defer, as loading may not work properly. Also, it is very small (only 18 lines).
And at the bottom, at the body’s <script> do like this
// ADD 'async'window.addEventListener('load',asyncfunction(ev){{{flutter_js}}{{flutter_build_config}}// ADD THIS LINE TO LOAD THE LIBRARY await_minisound.loader.load();// LEAVE THE REST IN PLACE// Download main.dart.js_flutter.loader.load({serviceWorker: {serviceWorkerVersion: {{flutter_service_worker_version}},},onEntrypointLoaded: function(engineInitializer){engineInitializer.initializeEngine().then(function(appRunner){appRunner.runApp();});},});});
// if you are using flutter, useimport"package:minisound/engine_flutter.dart"as minisound;
// and with plain dart useimport"package:minisound/engine.dart"as minisound;
// the difference is that flutter version allows you to load from assets, which is a concept specific to fluttervoidmain() async {
final engine = minisound.Engine();
// engine initialization
{
// you can pass `periodMs` as an argument, to change determines the latency (does not affect web). can cause crackles if too lowawait engine.init();
// for web: this should be executed after the first user interaction due to browsers' autoplay policyawait engine.start();
}
// there is a base `Sound` interface that is implemented by `LoadedSound` (which reads data from a defined length memory location) finalLoadedSound sound;
// sound loading
{
// there are also `loadSoundFile` and `loadSound` methods to load sounds from file (by filename) and `TypedData` respectfullyfinal sound =await engine.loadSoundAsset("asset/path.ext");
// you can get and set sound's volume (1 by default)
sound.volume *=0.5;
}
// playing, pausing and stopping
{
sound.play();
awaitFuture.delayed(sound.duration * .5); // waiting while the first half plays
sound.pause();
// when sound is paused, `resume` will continue the sound and `play` will start from the beginning
sound.resume();
sound.stop();
}
// looping
{
final loopDelay =constDuration(seconds:1);
sound.playLooped(delay: loopDelay); // sound will be looped with one second period// btw, sound duration does not account loop delayawaitFuture.delayed((sound.duration + loopDelay) *5); // waiting for sound to loop 5 times (with all the delays)
sound.stop();
}
// engine and sounds will be automatically disposed when gets garbage-collected
}
Generation
// you may want to read previous example first for more detailed explanationimport"package:minisound/engine_flutter.dart"as minisound;
voidmain() async {
final engine = minisound.Engine();
await engine.init();
await engine.start();
// `Sound` is also implemented by a `GeneratedSound` which is extended by `WaveformSound`, `NoiseSound` and `PulseSound` // there are four types of a waveform: sine, square, triangle and sawtooth; the type can be changed laterfinalWaveformSound wave = engine.genWaveform(WaveformType.sine);
// and three types of a noise: white, pink and brownian; CANNOT be changed laterfinalNoiseSound noise = engine.genNoise(NoiseType.white);
// pulsewave is basically a square wave with a different ratio between high and low levels (which is represented by the `dutyCycle`)finalPulseSound pulse = engine.genPulse(dutyCycle:0.25);
wave.play();
noise.play();
pulse.play();
// generated sounds have no duration, which makes sense if you think about it; for this reason they cannot be loopedawaitFuture.delayed(constDuration(seconds:1))
wave.stop();
noise.stop();
pulse.stop();
}
Recording
import"package:minisound/recorder.dart"as minisound;
voidmain() async {
// recorder records into memory using the wav format final recorder = minisound.Recorder();
// recording format characteristics can be changed via this function params
recorder.init();
// just starts the engineawait recorder.start();
awaitFuture.delayed(constDuration(seconds:1));
// returns what've been recordedfinal recording =await recorder.stop();
// all data is provided via buffer; sound can be used from it via `engine.loadSound(recording.buffer)`print(recording.buffer);
// recordings will be automatically disposed when gets garbage-collected
}
Migration guide
1.6.0 -> 2.0.0
Recording and generation APIs got heavily changed. See examples for new usage.
Sound autounloading logic got changed, now they depend on the sound object itself, rather than the engine.
// remove// sound.unload();
As a result, when Sound objects get garbage collected (which may be immediately after or not at the moment they go out of scope), they stop and unload. If you want to prevent this, you are probably doing something wrong, as this means you are creating an indefenetely played sound with no way to access it. Though this behaviour can still be disabled via the doAddToFinalizer parameter to sound loading and generation methods of the Engine class. However, it disables any finalization, so you’ll need to manage Sounds completely yourself. If you believe your usecase is valid, create a github issue and provide the code. Maybe it will change my mind.
1.4.0 -> 1.6.0
The main file (minisound.dart) became engine_flutter.dart.
// import "package:minisound/minisound.dart";// becomes two filesimport"package:minisound/engine_flutter.dart";
import"package:minisound/engine.dart";
Building the project
A Makefile is provided with recipes to build the project and ease development. Type make help to see a list of available commands.
To manually build the project, follow these steps:
Initialize the submodules:
git submodule update --init --recursive
Run the following commands to build the project using emcmake:
To install Miniconda in a server or cluster, users can use the command below.
Please remember to replace the <installation_shell_script> with the actual Miniconda installation shell script. In our
case, it is Miniconda3-latest-Linux-x86_64.sh.
Please also remember to replace the <desired_new_directory> with an actual directory absolute path.
The HAPPI_GWAS_2 pipeline is a command line based pipeline that can be ran on any Linux computing systems. It consists
of BLUP.py for best linear unbiased prediction, BLUE.py for best linear unbiased estimation, and HAPPI_GWAS.py for GWAS,
haploblock analysis, and candidate gene identification. The command and arguments of each tool are shown as below:
In order to use HAPPI_GWAS_chromosomewise.py, the file names or file prefixes of the vcf, genotype hapmap, genotype
data, genotype map, kinship, and covariance matrix files must be separated by chromosome and named using chromosome.
DDclient is a Perl client used to update dynamic DNS entries for accounts on Dynamic DNS Network Service Provider. It has the capability to update more than just dyndns and it can fetch your WAN-ipaddress in a few different ways.
When you start the ddclient image, you can adjust the configuration of the ddclient instance by passing one or more environment variables on the docker run command line.
UID
This variable is not mandatory and specifies the user id that will be set to run the application. It has default value 12345.
GID
This variable is not mandatory and specifies the group id that will be set to run the application. It has default value 12345.
AUTOUPGRADE
This variable is not mandatory and specifies if the container has to launch software update at startup or not. Valid values are 0 and 1. It has default value 0.
TZ
This variable is not mandatory and specifies the timezone to be configured within the container. It has default value Europe/Brussels.
DOCKRELAY
This variable is not mandatory and specifies the smtp relay that will be used to send email. Do not specify any if mail notifications are not required.
DOCKMAIL
This variable is not mandatory and specifies the mail that has to be used to send email. Do not specify any if mail notifications are not required.
DOCKMAILDOMAIN
This variable is not mandatory and specifies the address where the mail appears to come from for user authentication. Do not specify any if mail notifications are not required.
List-like types supporting O(1) append and snoc operations.
Installation
dlist is a Haskell package available from Hackage.
It can be installed with cabal or stack.
See the change log for the changes in each version.
Usage
Here is an example of “flattening” a Tree into a list of the elements in its
Leaf constructors:
importqualifiedData.DListasDListdataTreea=Leafa | Branch (Treea) (Treea)
flattenSlow::Treea-> [a]
flattenSlow = go
where
go (Leaf x) = [x]
go (Branch left right) = go left ++ go right
flattenFast::Treea-> [a]
flattenFast =DList.toList . go
where
go (Leaf x) =DList.singleton x
go (Branch left right) = go left `DList.append` go right
flattenSlow is likely to be slower than flattenFast:
flattenSlow uses ++ to concatenate lists, each of which is recursively
constructed from the left and rightTree values in the Branch
constructor.
flattenFast does not use ++ but constructs a composition of functions,
each of which is a “cons” introduced by DList.singleton ((x :)). The
function DList.toList applies the composed function to [], constructing
a list in the end.
To see the difference between flattenSlow and flattenFast, consider some
rough evaluations of the functions applied to a Tree:
flattenSlow (Branch (Branch (Leaf'a') (Leaf'b')) (Leaf'c'))
= go (Branch (Branch (Leaf'a') (Leaf'b')) (Leaf'c'))
= go (Branch (Leaf'a') (Leaf'b')) ++ go (Leaf'c')
= (go (Leaf'a') ++ go (Leaf'b')) ++"c"= ("a"++"b") ++"c"= ('a':[]++"b") ++"c"= ('a':"b") ++"c"='a':"b"++"c"='a':'b':[]++"c"='a':'b':"c"
The left-nested ++ in flattenSlow results in intermediate list constructions
that are immediately discarded in the evaluation of the outermost ++. On the
other hand, the evaluation of flattenFast involves no intermediate list
construction but rather function applications and newtype constructor wrapping
and unwrapping. This is where the efficiency comes from.
Warning! Note that there is truth in the above, but there is also a lot of
hand-waving and intrinsic complexity. For example, there may be GHC rewrite
rules that apply to ++, which will change the actual evaluation. And, of
course, strictness, laziness, and sharing all play a significant role. Also, not
every function in the dlist package is the most efficient for every situation.
Moral of the story: If you are using dlist to speed up your code, check
to be sure that it actually does. Benchmark!
Design Notes
These are some notes on design and development choices made for the dlist
package.
Avoid ++
The original intent of Hughes’ representation of lists as first-class functions
was to provide an abstraction such that the list append operation found in
functional programming languages (and now called ++ in Haskell) would not
appear in left-nested positions to avoid duplicated structure as lists are
constructed. The lesson learned by many people using list over the years is that
the append operation can appear, sometimes surprisingly, in places they don’t
expect it.
One of our goals is for the dlist package to avoid surprising its users with
unexpected insertions of ++. Towards this end, there should be a minimal set
of functions in dlist in which ++ can be directly or indirectly found. The
list of known uses of ++ includes:
If any future requested functions involve ++ (e.g. via fromList), the burden
of inclusion is higher than it would be otherwise.
Abstraction
The DList representation and its supporting functions (e.g. append, snoc,
etc.) rely on an invariant to preserve its safe use. That is, without this
invariant, a user may encounter unexpected outcomes.
(We use safety in the sense that the semantics are well-defined and expected,
not in the sense of side of referential transparency. The invariant does not
directly lead to side effects in the dlist package, but a program that uses an
unsafely generated DList may do something surprising.)
The invariant is that, for any xs :: DList a:
fromList (toList xs) = xs
To see how this invariant can be broken, consider this example:
It would be rather unhelpful and surprising to find (xs `snoc` 1) turned out
to be the empty list.
To preserve the invariant on DList, we provide it as an abstract type in the
Data.DList module. The constructor, UnsafeDList, and record label,
unsafeApplyDList, are not exported because these can be used, as shown above,
to break the invariant.
All of that said, there have been numerous requests to export the DList
constructor. We are not convinced that it is necessary, but we are convinced
that users should decide for themselves.
To use the constructor and record label of DList, you import them as follows:
If you are using Safe Haskell, you may need to add this at the top of your
module:
{-# LANGUAGE Trustworthy #-}
Just be aware that the burden of proof for safety is on you.
References
These are various references where you can learn more about difference lists.
Research
A novel representation of lists and its application to the function
“reverse.” John Hughes. Information Processing Letters. Volume 22, Issue 3.
1986-03. Pages 141-144. PDF
This is the original published source for a representation of lists as
first-class functions.
Marvel Api Android Components Architecture in a Modular Word is a sample project that presents modern, 2020 approach to Android application development using Kotlin and latest tech-stack.
A UI/Material Design sample. The interface of the app is deliberately kept simple to focus on architecture. Check out Plaid instead.
A real production app with network access, user authentication, etc. Check out the Google I/O app, Santa Tracker or Tivi for that.
Model-View-ViewModel (ie MVVM) is a template of a client application architecture MVVM
MarvelHeroes is a demo application based on modern Android application tech-stacks and MVVM architecture.Fetching data from the network and integrating persisted data in the database via repository pattern.
Clean Archetecture This is a sample app that is part of a blog post I have written about how to architect android application using the Uncle Bob’s clean architecture approach.
Idiomatic KotlinContains all the code presented in the Idiomatic Kotlin tutorial series.
UseCase
You can reference the good use cases of this library in the below repositories.
Pokedex – 🗡️ Android Pokedex using Hilt, Motion, Coroutines, Flow, Jetpack (Room, ViewModel, LiveData) based on MVVM architecture.
DisneyMotions – 🦁 A Disney app using transformation motions based on MVVM (ViewModel, Coroutines, LiveData, Room, Repository, Koin) architecture.
MarvelHeroes – ❤️ A sample Marvel heroes application based on MVVM (ViewModel, Coroutines, LiveData, Room, Repository, Koin) architecture.
TheMovies2 – 🎬 A demo project using The Movie DB based on Kotlin MVVM architecture and material design & animations.
ForUiRef -A curated list of awesome Android UI/UX libraries.
AndroidUtilsSample Android Utils app contain simple code for starting a app
List Of Open ApisThis repo is a collection of AWESOME APIs for developers. Feel free to Star and Fork. Any comments, suggestions? Let us know. we love PRs :), please follow the awesome list.
The project objective is to enhance the usage experience of the Codable protocol using the macro provided by Swift 5.9 and to address the shortcomings of various official versions.
Feature
Default value
Basic type automatic convertible, between StringBoolNumber etc.
Custom multiple CodingKey
Nested Dictionary CodingKey
Automatic compatibility between camel case and snake case
Convenience Codable subclass
Transformer
Installation
CocoaPods
pod 'CodableWrapper', :git => 'https://github.com/winddpan/CodableWrapper.git'