A strong foundation for building predictable and straight-forward Rust UI toolkits. Reclutch is:
Bare: Very little UI code is included. In practice it’s a utility library which makes very little assumptions about the toolkit or UI.
Platform-agnostic: Although a default display object is provided, the type of display object is generic, meaning you can build for platforms other than desktop. For example you can create web applications simply by using DOM nodes as display objects while still being efficient, given the retained-mode design.
Reusable: Provided structures such as unbound queue handlers allow for the reuse of common logical components across widgets.
Overview
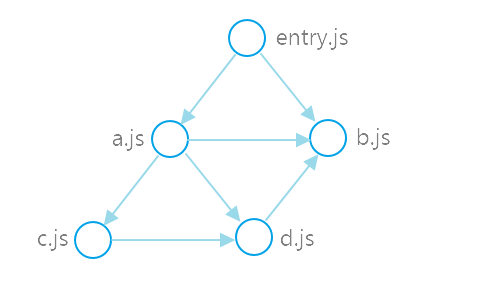
Reclutch implements the well-known retained-mode widget ownership design within safe Rust, following along the footsteps of popular desktop frameworks. To implement this behavior, three core ideas are implemented:
A widget ownership model with no middleman, allowing widgets to mutate children at any time, but also collect children as a whole to make traversing the widget tree a trivial task.
A robust event queue system with support for futures, crossbeam and winit event loop integration, plus a multitude of queue utilities and queue variations for support in any environment.
An event queue abstraction to facilitate just-in-time event coordination between widgets, filling any pitfalls that may arise when using event queues. Beyond this, it also moves the code to handle queues to the constructor, presenting an opportunity to modularize and reuse logic across widgets.
Note for MacOS
There appears to be a bug with shared OpenGL textures on MacOS. As a result, the opengl example won’t work correctly. For applications that require rendering from multiple contexts into a single texture, consider using Vulkan or similar.
(Note: you can switch out the reclutch::widget::WidgetChildrens above with your own trait using #[widget_children_trait(...)])
Then all the other functions (draw, update, maybe even bounds for parent clipping) are propagated manually (or your API can have a function which automatically and recursively invokes for both parent and child);
fndraw(&mutself,display:&mutdynGraphicsDisplay){// do our own rendering here...// ...then propagate to childrenfor child inself.children_mut(){
child.draw(display);}}
Note:WidgetChildren requires that Widget is implemented.
The derive functionality is a feature, enabled by default.
Rendering
Rendering is done through “command groups”. It’s designed in a way that both a retained-mode renderer (e.g. WebRender) and an immediate-mode renderer (Direct2D, Skia, Cairo) can be implemented.
The API also supports Z-Order.
structVisualWidget{command_group:CommandGroup,}implWidgetforVisualWidget{// --snip--fnupdate(&mutself,_aux:&mut()){ifself.changed{// This simply sets an internal boolean to "true", so don't be afraid to call it multiple times during updating.self.command_group.repaint();}}// Draws a nice red rectangle.fndraw(&mutself,display:&mutdynGraphicsDisplay,_aux:&mut()){letmut builder = DisplayListBuilder::new();
builder.push_rectangle(Rect::new(Point::new(10.0,10.0),Size::new(30.0,50.0)),GraphicsDisplayPaint::Fill(Color::new(1.0,0.0,0.0,1.0).into()),None);// Only pushes/modifies the command group if a repaint is needed.self.command_group.push(display,&builder.build(),Default::default(),None,true);draw_children();}// --snip--}
Updating
The update method on widgets is an opportunity for widgets to update layout, animations, etc. and more importantly handle events that have been emitted since the last update.
Widgets have an associated type; UpdateAux which allows for a global object to be passed around during updating. This is useful for things like updating a layout.
Here’s a simple example;
typeUpdateAux = Globals;fnupdate(&mutself,aux:&mutGlobals){if aux.layout.node_is_dirty(self.layout_node){self.bounds = aux.layout.get_node(self.layout_node);self.command_group.repaint();}self.update_animations(aux.delta_time());// propagation is done manuallyfor child inself.children_mut(){
child.update(aux);}// If your UI doesn't update constantly, then you must check child events *after* propagation,// but if it does update constantly, then it's more of a micro-optimization, since any missed events// will come back around next update.//// This kind of consideration can be avoided by using the more "modern" updating API; `verbgraph`,// which is discussed in the "Updating correctly" section.for press_event inself.button_press_listener.peek(){self.on_button_press(press_event);}}
Updating correctly
The above code is fine, but for more a complex UI then there is the possibility of events being processed out-of-order.
To fix this, Reclutch has the verbgraph module; a facility to jump between widgets and into their specific queue handlers.
In essence, it breaks the linear execution of update procedures so that dependent events can be handled even if the primary update function has already be executed.
This is best shown through example;
fnnew() -> Self{let graph = verbgraph!{Selfas obj,Auxas aux,// the string "count_up" is the tag used to identify procedures.// they can also overlap."count_up" => event in &count_up.event => {
click => {// here we mutate a variable that `obj.template_label` implicitly/indirectly depends on.
obj.count += 1;// Here template_label is assumed to be a label whose text uses a template engine// that needs to be explicitly rendered.
obj.template_label.values[0] = obj.count.to_string();// If we don't call this then `obj.dynamic_label` doesn't// get a chance to respond to our changes in this update pass.// This doesn't invoke the entire update cycle for `template_label`, only the specific part we care about; `"update_template"`.
reclutch_verbgraph::require_update(&mut obj.template_label, aux,"update_template");// "update_template" refers to the tag.}}};// ...}fnupdate(&mutself,aux:&mutAux){for child inself.children_mut(){
child.update(aux);}
reclutch_verbgraph::update_all(self, aux);}
In the verbgraph module is also the Event trait, which is required to support the syntax seen in verbgraph!.
get_key is used to find the correct closure to execute given an event
and unwrap_as_ is used to extract the inner information from within the
given closure (because once get_key is matched then we can be certain it
is of a certain variant).
This package provides an easy way to quickly set up AdminLTE v3 with Laravel (7 or higher). It has no others requirements and dependencies besides Laravel, so you can start building your admin panel immediately. The package provides a blade template that you can extend and an advanced menu configuration system. Also, and optionally, the package offers a set of AdminLTE styled authentication views that you can use in replacement of the ones that are provided by the legacy laravel/ui authentication scaffolding.
If you want to use an older Laravel or AdminLTE version, review the following package releases:
Releases 1.x:
These releases supports Laravel 5 and include AdminLTE v2
Releases 2.x:
These releases supports Laravel 6 and include AdminLTE v2
Releases 3.x (<=3.8.6):
These releases supports Laravel 6 and include AdminLTE v3
You can report issues or ask questions in the issues section. Please, start your issue with [BUG] and your question with [QUESTION] in the subject.
If you have a question, it is recommended to make a search over the closed issues first.
To submit a Pull Request, fork this repository and create a new branch to commit your new changes there. Finally, open a Pull Request from your new branch. Refer to the contribution guidelines for detailed instructions. When submitting a Pull Request take the next notes into consideration:
Verify that the Pull Request doesn’t introduce a high downgrade on the code quality.
If the Pull Request adds a new feature, consider adding a proposal of the documentation for this feature too.
Keep the package focused, don’t add special support to other packages or to solve very particular situations. These changes will make the package harder to maintain.
It is not always obvious where import x from 'module' should look to find the file behind module, it depends on module resolution algorithms, which are specific for module bundlers, module syntax specs, etc.. deps-walker uses resolve package, which implements NodeJS module resolution behavior. You may configure NodeJS resolve via available options:
Welcome to my personal dotfiles repository, tailored for the 🐟 Fish shell. These configurations are designed to create a baseline for my development environment, integrating seamlessly with VSCode, Starship, tmux, etc.
Key Features
Prompt Customization with ⭐️🚀 Starship: A sleek, informative command-line interface built in Rust.
Effortless Dotfile Management: Uses chezmoi for a streamlined process to update, install, and configure my environment with a simple one-line command.
Intelligent OS Detection: Automatically installs OS-specific packages, ensuring compatibility and ease of setup.
User-Guided Installation Script: Tailored setup with interactive prompts to select only the tools I need.
Enhanced File Listing with eza: A more colorful and user-friendly ls command.
Optimized Tmux Configuration: Benefit from a powerful Tmux setup by gpakosz, enhancing your terminal multiplexer experience.
Getting Started
Compatibility
Note: This setup is currently optimized for macOS and Debian-based Linux distributions.
Installation
To install, choose one of the following methods and execute the command in my terminal:
Curl:
sh -c "$(curl -fsLS get.chezmoi.io)" -- init --apply mmena1
Wget:
sh -c "$(wget -qO- get.chezmoi.io)" -- init --apply mmena1
Keep my environment fresh and up-to-date with a simple command:
chezmoi update
This will fetch and apply the latest changes from the repository, ensuring my setup remains optimal.
Under the Hood
Custom Fish Scripts
Leveraging the best of oh-my-zsh, I’ve crafted custom Fish scripts, including git and eza abbreviations, enriching my shell without the need for plugins.
Chezmoi: The Backbone
At the heart of my dotfile management is Chezmoi, a robust tool offering templating features to dynamically adapt scripts across various systems, alongside the capability to preview and verify scripts before execution.
Modular Task Management
A task-based approach is used for managing the setup and configuration of my development environment. Instead of running a monolithic script, the setup process is broken down into discrete tasks that can be individually registered, managed, and executed.
Key features of the task management system:
Task Registration: Each setup component is registered as a task with a name, description, list of dependencies, and execution function.
Dependency Resolution: Tasks specify their dependencies, ensuring they’re executed in the correct order. For example, package installation requires Homebrew to be installed first (only for macOS).
Interactive Execution: Before each task runs, I’m prompted to confirm, letting me customize my setup process.
Error Handling: If a task fails, I can choose to continue with the remaining tasks or abort the setup.
Modular Implementation: Setup components are organized into modules (package management, shell configuration, development tools, etc.) that can be maintained independently.
This approach makes the setup process more maintainable, flexible, and user-friendly. New tasks can be added without modifying existing code, and dependencies are automatically resolved to ensure a smooth setup experience.
Iforgor is a customisable and easy to use command line tool to manage code samples.
It’s a good way to quickly get your hand on syntax you dont remember right from your terminal without wasting time looking on the internet.
Installation
Method :
Creates symlinks of iforgor.py and the snippets folder to /usr/local/bin. So that it can be run from anywhere on the terminal.
Requirements :
Python.
Git.
The colorama python module.
Step by step procedure :
Open a terminal and cd into the directory you want to install the program into.
Run “./setup.sh” as root (it has to be run as root since it needs to create files in /usr/local/bin), add the ungit argument to remove github related files and folders like the readme and license.
Run “iforgor -h”
If it works, the install was successful.
You can then delete setup.sh
Uninstall:
To uninstall, simply delete the ‘iforgor’ and ‘snippets’ symlinks in /usr/local/bin.
Then delete the iforgor folder.
Iforgor 101
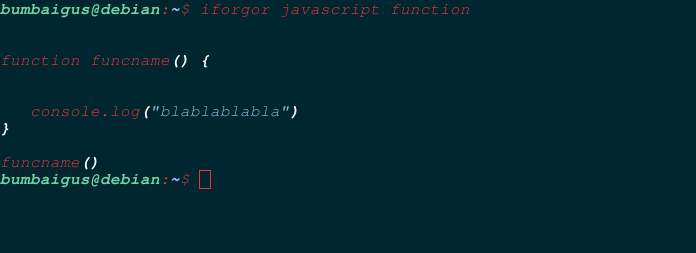
To display a piece of code, run the following.
iforgor LANGUAGE SNIPPET
The language argument represents a folder in the “snippets” directory.
You can add any language you want by creating a folder in it.
The snippet argument represents a *.txt file in the specified language directory that containd the code sample you want to display.
You can add any code sample by creating a *.txt in a desired language folder.
So if you want to add a function sample for the, lets say Rust language for example.
You will have to create a directory named “rust” in the snippets folder.
And create a function.txt file in the rust folder with the code you want inside.
You can then print it out by running iforgor rust function
Pro tips:
Languages and snippets are case insensitive. So you can run ‘iforgor lAnGuAgE sNiPpeT’.
You dont need to do the setup process, but its required if you want to be able to run iforgor easily from anywhere.
There are default snippets yes, but iforgor is designed to be customized, dont hesitate to add your own custom snippets and languages.
Screenshots:
Compatibility
Linux
This should work on pretty much any linux distro, but i can make mistakes, so dont hesitate opening an issue if you face problems.
Iforgor was tested on:
Debian 11 : Working
Void Linux : Working
Arch Linux : Working
BSDs and other unix based operating systems.
Those are less certain to work, but you can still give it a try.
Tested on:
FreeBSD : Working
OpenBSD : Working
Want to contribute ?
Sure. All help is accepted.
The code is very commented if you want to take a look at it.
PLEASE dont forget to star the project if you find it interesting, it helps out a ton.
A high-level real-time audio playback, generation and recording library based on miniaudio. The library offers basic functionality and quite low latency. Supports MP3, WAV and FLAC formats.
Platform support
Platform
Tested
Supposed to work
Unsupported
Android
SDK 31, 19
SDK 16+
SDK 15-
iOS
None
Unknown
Unknown
Windows
11, 7 (x64)
Vista+
XP-
macOS
None
Unknown
Unknown
Linux
Fedora 39-40, Mint 22
Any
None
Web
Chrome 93+, Firefox 79+, Safari 16+
Browsers with an AudioWorklet support
Browsers without an AudioWorklet support
Migration
There was some pretty major changes in 2.0.0 version, see the migration guide down below.
Getting started on the web
While the main script is quite large, there is a loader script provided. Include it in the web/index.html file like this
It is highly recommended NOT to make the script defer, as loading may not work properly. Also, it is very small (only 18 lines).
And at the bottom, at the body’s <script> do like this
// ADD 'async'window.addEventListener('load',asyncfunction(ev){{{flutter_js}}{{flutter_build_config}}// ADD THIS LINE TO LOAD THE LIBRARY await_minisound.loader.load();// LEAVE THE REST IN PLACE// Download main.dart.js_flutter.loader.load({serviceWorker: {serviceWorkerVersion: {{flutter_service_worker_version}},},onEntrypointLoaded: function(engineInitializer){engineInitializer.initializeEngine().then(function(appRunner){appRunner.runApp();});},});});
// if you are using flutter, useimport"package:minisound/engine_flutter.dart"as minisound;
// and with plain dart useimport"package:minisound/engine.dart"as minisound;
// the difference is that flutter version allows you to load from assets, which is a concept specific to fluttervoidmain() async {
final engine = minisound.Engine();
// engine initialization
{
// you can pass `periodMs` as an argument, to change determines the latency (does not affect web). can cause crackles if too lowawait engine.init();
// for web: this should be executed after the first user interaction due to browsers' autoplay policyawait engine.start();
}
// there is a base `Sound` interface that is implemented by `LoadedSound` (which reads data from a defined length memory location) finalLoadedSound sound;
// sound loading
{
// there are also `loadSoundFile` and `loadSound` methods to load sounds from file (by filename) and `TypedData` respectfullyfinal sound =await engine.loadSoundAsset("asset/path.ext");
// you can get and set sound's volume (1 by default)
sound.volume *=0.5;
}
// playing, pausing and stopping
{
sound.play();
awaitFuture.delayed(sound.duration * .5); // waiting while the first half plays
sound.pause();
// when sound is paused, `resume` will continue the sound and `play` will start from the beginning
sound.resume();
sound.stop();
}
// looping
{
final loopDelay =constDuration(seconds:1);
sound.playLooped(delay: loopDelay); // sound will be looped with one second period// btw, sound duration does not account loop delayawaitFuture.delayed((sound.duration + loopDelay) *5); // waiting for sound to loop 5 times (with all the delays)
sound.stop();
}
// engine and sounds will be automatically disposed when gets garbage-collected
}
Generation
// you may want to read previous example first for more detailed explanationimport"package:minisound/engine_flutter.dart"as minisound;
voidmain() async {
final engine = minisound.Engine();
await engine.init();
await engine.start();
// `Sound` is also implemented by a `GeneratedSound` which is extended by `WaveformSound`, `NoiseSound` and `PulseSound` // there are four types of a waveform: sine, square, triangle and sawtooth; the type can be changed laterfinalWaveformSound wave = engine.genWaveform(WaveformType.sine);
// and three types of a noise: white, pink and brownian; CANNOT be changed laterfinalNoiseSound noise = engine.genNoise(NoiseType.white);
// pulsewave is basically a square wave with a different ratio between high and low levels (which is represented by the `dutyCycle`)finalPulseSound pulse = engine.genPulse(dutyCycle:0.25);
wave.play();
noise.play();
pulse.play();
// generated sounds have no duration, which makes sense if you think about it; for this reason they cannot be loopedawaitFuture.delayed(constDuration(seconds:1))
wave.stop();
noise.stop();
pulse.stop();
}
Recording
import"package:minisound/recorder.dart"as minisound;
voidmain() async {
// recorder records into memory using the wav format final recorder = minisound.Recorder();
// recording format characteristics can be changed via this function params
recorder.init();
// just starts the engineawait recorder.start();
awaitFuture.delayed(constDuration(seconds:1));
// returns what've been recordedfinal recording =await recorder.stop();
// all data is provided via buffer; sound can be used from it via `engine.loadSound(recording.buffer)`print(recording.buffer);
// recordings will be automatically disposed when gets garbage-collected
}
Migration guide
1.6.0 -> 2.0.0
Recording and generation APIs got heavily changed. See examples for new usage.
Sound autounloading logic got changed, now they depend on the sound object itself, rather than the engine.
// remove// sound.unload();
As a result, when Sound objects get garbage collected (which may be immediately after or not at the moment they go out of scope), they stop and unload. If you want to prevent this, you are probably doing something wrong, as this means you are creating an indefenetely played sound with no way to access it. Though this behaviour can still be disabled via the doAddToFinalizer parameter to sound loading and generation methods of the Engine class. However, it disables any finalization, so you’ll need to manage Sounds completely yourself. If you believe your usecase is valid, create a github issue and provide the code. Maybe it will change my mind.
1.4.0 -> 1.6.0
The main file (minisound.dart) became engine_flutter.dart.
// import "package:minisound/minisound.dart";// becomes two filesimport"package:minisound/engine_flutter.dart";
import"package:minisound/engine.dart";
Building the project
A Makefile is provided with recipes to build the project and ease development. Type make help to see a list of available commands.
To manually build the project, follow these steps:
Initialize the submodules:
git submodule update --init --recursive
Run the following commands to build the project using emcmake:
To install Miniconda in a server or cluster, users can use the command below.
Please remember to replace the <installation_shell_script> with the actual Miniconda installation shell script. In our
case, it is Miniconda3-latest-Linux-x86_64.sh.
Please also remember to replace the <desired_new_directory> with an actual directory absolute path.
The HAPPI_GWAS_2 pipeline is a command line based pipeline that can be ran on any Linux computing systems. It consists
of BLUP.py for best linear unbiased prediction, BLUE.py for best linear unbiased estimation, and HAPPI_GWAS.py for GWAS,
haploblock analysis, and candidate gene identification. The command and arguments of each tool are shown as below:
In order to use HAPPI_GWAS_chromosomewise.py, the file names or file prefixes of the vcf, genotype hapmap, genotype
data, genotype map, kinship, and covariance matrix files must be separated by chromosome and named using chromosome.