This library includes some predefined vector structs:
LA::Vector1
LA::Vector2
LA::Vector3
LA::Vector4
These structs implement a basic set of functionality
(let’s take LA::Vector2 as an example):
require"linalg"includeLA# so we can use `Vector2` instead of `LA::Vector2`# Predefined constants:# * `COMPONENTS` (needed by the macros)# Predefined class methods (to enable stuff like [v1, v2, v3].sum)# * `zero`, `one`# * one for each componentpVector2::COMPONENTS# => [:x, :y]pVector2.zero # => LA::Vector2(@x = 0.0, @y = 0.0)pVector2.one # => LA::Vector2(@x = 1.0, @y = 1.0)pVector2.x # => LA::Vector2(@x = 1.0, @y = 0.0)pVector2.y # => LA::Vector2(@x = 0.0, @y = 1.0)
a =Vector2.new(1.0, 2.0)
b =Vector2.new(3.0, 4.0)
p-b # => LA::Vector2(@x = -3.0, @y = -4.0)p a + b # => LA::Vector2(@x = 4.0, @y = 6.0)p a - b # => LA::Vector2(@x = -2.0, @y = -2.0)p b.length # => 5.0p b.squared_length # => 25.0p b *2.0# => LA::Vector2(@x = 6.0, @y = 8.0)p b /2.0# => LA::Vector2(@x = 1.5, @y = 2.0)p a.dot(b) # => 11.0# The cross product is only implemented for Vector3
x =Vector3.x
y =Vector3.y
p x.cross(y) # => LA::Vector3(@x = 0.0, @y = 0.0, @z = 1.0)
Custom Structs
Because it is (currently?)
not possible for structs to inherit from non-abstract structs
(like LA::Vector3), there are abstract versions of all the VectorN structs:
LA::AVector1
LA::AVector2
LA::AVector3
LA::AVector4
These implement all of the VectorN functions,
in fact the “implementation” von LA::Vector3 looks like this:
structVector3 < AVector3end
Example 1
require"linalg"structNormal < LA::AVector3# The methods of `LA::AVectors3` are defined# using the following macros# `define_vector_op(:+)`# `define_vector_op(:-)`# `define_unop(:-)`# `define_op(:*)`# `define_op(:/)`# `define_dot`# `define_length` (defines `.length`, `.squared_length` and `.normalize`)# In this example, we need to overwrite some of those,# because the result of (e.g.) adding two normals# is not neccessarily a “valid” normal.## Luckily there are extended forms of the macros from before# that we can use overwrite the old methods# and specify a new type for the result
define_vector_op(:+, other_class:Normal, result_class:LA::Vector3)
define_vector_op(:-, other_class:Normal, result_class:LA::Vector3)
define_op(:*, result_class:LA::Vector3)
define_op(:/, result_class:LA::Vector3)
# Additionally we could define those ops with types other than `Float64`
define_op(:*, other_class:Int32, result_class:LA::Vector3)
define_op(:/, other_class:Int32, result_class:LA::Vector3)
defself.oneraise"This makes no sense in the context of a normal"enddefself.zeroraise"This makes no sense in the context of a normal"endend
Example 2
Let’s make an even more “custom” struct!
require"linalg"# In this case we can not inherit from `LA::Vector3`,# because our components have names other than `.x`, `.y`, `.z`.structColorCOMPONENTS= [:r, :g, :b]
# `define_vector` defines all the vector methods# (see: __Example 1__) at once
define_vector
# Multiplication of two vectors is not defined by default,# but here it is handy to blend two colors
define_vector_op(:*)
end
red =Color::R
other =Color.new(0.8, 0.2, 0.7)
p red * other # => Color(@r=0.8, @g=0.0, @b=0.0)
Swizzling
Swizzling
is not „enabled“ (the macros are not included) for the default vector structs,
but it can be included via the define_swizzling(target_size, target = :tuple, signed = false) macro.
structVec2 < LA::AVector2# By default, the swizzled methods return a tuple with the values
define_vector_swizzling(2)
endstructVec3 < LA::AVector3# The other valid options are to pass `:array` or a class name as the `target`
define_vector_swizzling(3, target::array)
# If `signed` is set to `true`,# in addition to methods like `vector.xyz`# the macro will create “signed” methods# like `vector._x_y_z` or `.vector.x_zy`
define_vector_swizzling(2, target:Vec2, signed:true)
end
a =Vec2.new(1.0, 2.0)
p a.xy # => {1.0, 2.0}p a.yx # => {2.0, 1.0}p a.yy # => {2.0, 2.0}
b =Vec3.new(1.0, 2.0, 3.0)
p b.xxz # => [1.0, 1.0, 3.0]p b.xy # => Vec2(@x = 1.0, @y = 2.0)p b._y_y # => Vec2(@x = -2.0, @y = -2.0)
There are two datasets in the data directory – the first containing legislative information on moths (Legislative), the second containing the measured spectra (Spectra).
The files are available in two formats – .csv and .xlsx.
Legislative file contains the following columns:
ID – Individual identifier (species–number)
Species – Diachrysia chrysitis or Diachrysia stenochrysis
Sex – Male (♂) or Female (♀)
Year_catch – year of the moth catch
Day_catch – day of the year when the moth was caught
Locality – place where the moth was caught
UTM_code – zone in UTM coordinate system
Longitude – east–west position in degrees
Latitude – north–south position in degrees
Feature_level – level of marking the morphological feature, where 1 means weak, 2 means strong, 3 means very strong
Spectra file contains the following columns:
ID – Individual identifier (species–number)
Species – Diachrysia chrysitis or Diachrysia stenochrysis
Scale – part of the scale on which the spectrometer measurement was made (Glass or Brown)
400-2100 – spectral band number
Reproduction
Open the diachrysia-classification.Rproj project file in RStudio.
Run 01_randomforest.R to build classification models, assess the performance of classification at the general and individual level and determine the importance of spectral features.
Run 02_KS_test.R to determine importance of the spectral bands for species discrimination using Kolmogorov–Smirnov test.
Run 03_LDA_best_features.R to determine the most useful spectral bands for species classification using Linear Discriminant Analysis and D-statistic.
Run 04_LDA_combinations.R to determine the minimum set of spectral features to distinguish species with 100% accuracy.
Results
The code results were saved in results directory:
ks-test.csv – importance of the spectral bands for species discrimination determined by D-statistic
rf-importance.csv – average importance of the spectral features for classification in the random forest models
NAME
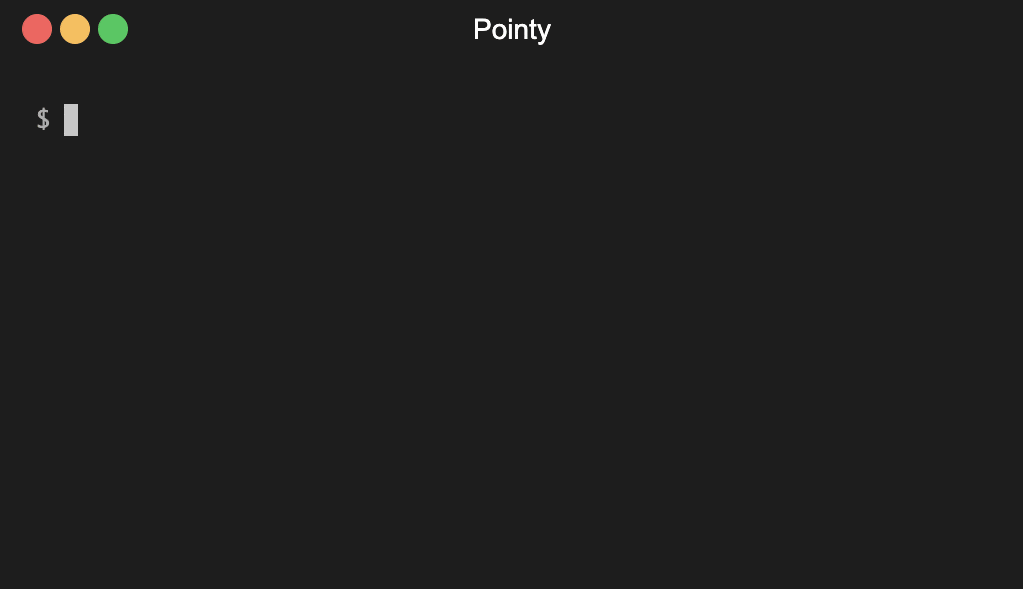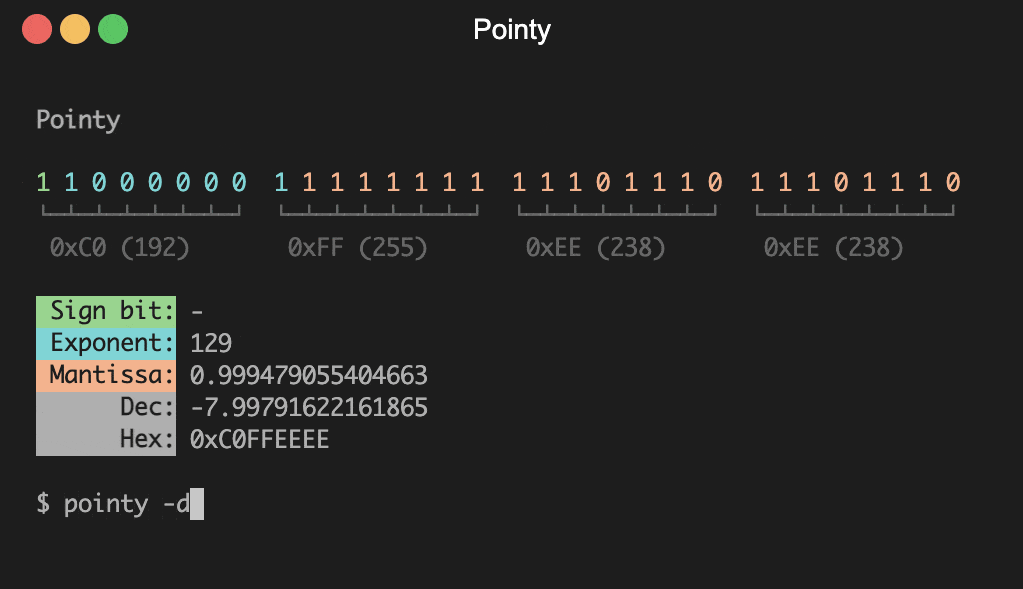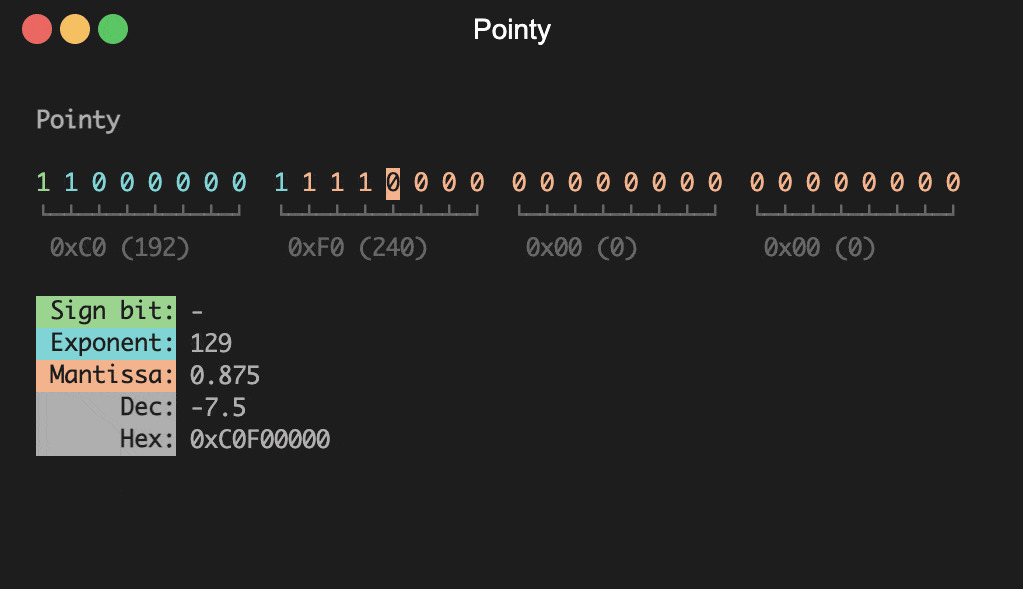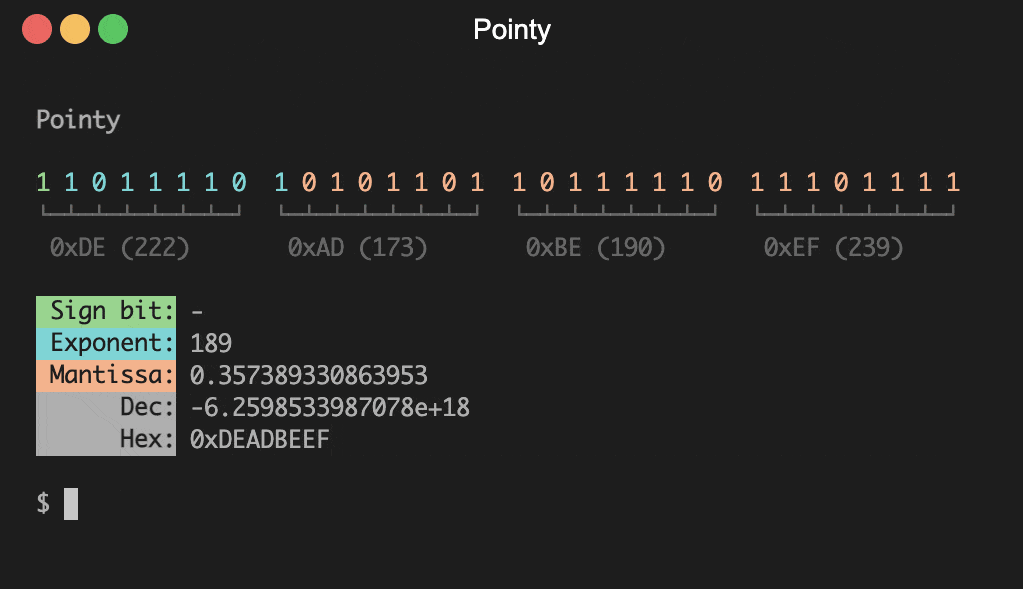
pointy - Present IEEE 754 floating point values
SYNOPSIS
# Run with no options for interactive mode
pointy
DESCRIPTION
Provides a visual representation of IEEE 754 floating point
numbers. In interactive mode the following keys are available:
- Left / right arrow-keys to navigate bit array
- Up / down arrow-keys to flip bits on or off
- 1 / 0 keys to input bits manually
- + / - keys to adjust colour index
- Delete / backspace to set current bit to 0
- Tab key / ^I (Control-I) to switch fields for direct input
- ? / H key to show this help document
Options
[-\? | -help ]
Show this help document and quit
[-decimal] <value>
Present decimal <value> and quit
[-hexadecimal] <value>
Present hexadecimal <value> and quit
[-nocolour]
Do not use colours (colours are 16-bit)
[-colour] <index>
Adjust colour index (range: -80 to 175)
[-unicode]
Use Unicode characters (default is DEC Special Graphics)
[-ascii]
Use ASCII characters only
[-version]
Print current version and quit
Examples
# Display hex value with no colour
pointy -n -hex deadbeef
# Display decimal value
pointy -d 123
BUGS
* None known
SOURCE AVAILABILITY
Source code is available on GitHub (https://github.com/thunderpoot/pointy/)
CREDITS
Devon (https://github.com/telnet23) for help with Perl syntax
and mathematics
Bartosz Ciechanowski (https://ciechanow.ski/exposing-floating-point/)
and (https://float.exposed/)
AUTHOR
Underwood, "<underwood@underwood.network>"
COPYRIGHT
Copyright (c) 2023, All Rights Reserved.
You may modify and redistribute this software only if this documentation
remains intact.
SEE ALSO
float(3), math(3), complex(3)
RFC 6340 (https://www.rfc-editor.org/rfc/rfc6340.html)
STANDARDS
Floating-point arithmetic conforms to the ISO/IEC 9899:2011 standard.
NAME
pointy - Present IEEE 754 floating point values
SYNOPSIS
# Run with no options for interactive mode
pointy
DESCRIPTION
Provides a visual representation of IEEE 754 floating point
numbers. In interactive mode the following keys are available:
- Left / right arrow-keys to navigate bit array
- Up / down arrow-keys to flip bits on or off
- 1 / 0 keys to input bits manually
- + / - keys to adjust colour index
- Delete / backspace to set current bit to 0
- Tab key / ^I (Control-I) to switch fields for direct input
- ? / H key to show this help document
Options
[-\? | -help ]
Show this help document and quit
[-decimal] <value>
Present decimal <value> and quit
[-hexadecimal] <value>
Present hexadecimal <value> and quit
[-nocolour]
Do not use colours (colours are 16-bit)
[-colour] <index>
Adjust colour index (range: -80 to 175)
[-unicode]
Use Unicode characters (default is DEC Special Graphics)
[-ascii]
Use ASCII characters only
[-version]
Print current version and quit
Examples
# Display hex value with no colour
pointy -n -hex deadbeef
# Display decimal value
pointy -d 123
BUGS
* None known
SOURCE AVAILABILITY
Source code is available on GitHub (https://github.com/thunderpoot/pointy/)
CREDITS
Devon (https://github.com/telnet23) for help with Perl syntax
and mathematics
Bartosz Ciechanowski (https://ciechanow.ski/exposing-floating-point/)
and (https://float.exposed/)
AUTHOR
Underwood, "<underwood@underwood.network>"
COPYRIGHT
Copyright (c) 2023, All Rights Reserved.
You may modify and redistribute this software only if this documentation
remains intact.
SEE ALSO
float(3), math(3), complex(3)
RFC 6340 (https://www.rfc-editor.org/rfc/rfc6340.html)
STANDARDS
Floating-point arithmetic conforms to the ISO/IEC 9899:2011 standard.
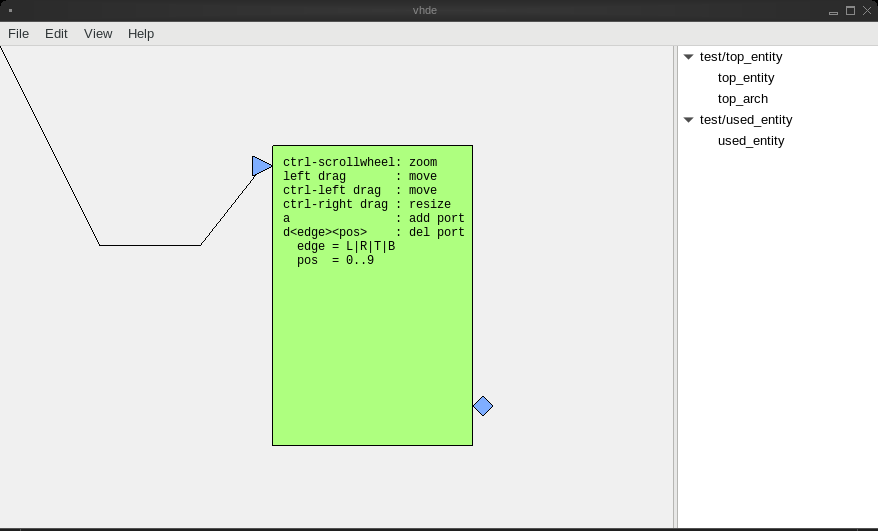
With the VHDL Diagram Editor you can create hierarchical VHDL designs where
only the lowest level is written as text and the others are presented in a
diagram as graphical components that can be connected to each other. Each
diagram defines its inputs and outputs so it can be used as a component in
a higher level diagram.
the functional structure of the diagrams is stored in one set of files,
while the layout information is stored in others.
the file content is sorted/organized in such a way that it is easy to
compare two versions of a file and see what was changed
it does not integrate version control, but because it stores things in
a version control friendly format, you can use any version control
system you want
it does not have an integrated editor for VHDL code, because existing
editors are better than a custom one would ever be
Currently when you select Open from the File menu, the application loads the
project defined in the test/exampleproject.vhde file. You can switch between
the entities and architectures in the project overview on the right, you can
interact with the diagram and optionally save your changes back to disk before
you close the application.
Dependencies
VHDE requires the following packages to be installed:
With the VHDL Diagram Editor you can create hierarchical VHDL designs where
only the lowest level is written as text and the others are presented in a
diagram as graphical components that can be connected to each other. Each
diagram defines its inputs and outputs so it can be used as a component in
a higher level diagram.
the functional structure of the diagrams is stored in one set of files,
while the layout information is stored in others.
the file content is sorted/organized in such a way that it is easy to
compare two versions of a file and see what was changed
it does not integrate version control, but because it stores things in
a version control friendly format, you can use any version control
system you want
it does not have an integrated editor for VHDL code, because existing
editors are better than a custom one would ever be
Currently when you select Open from the File menu, the application loads the
project defined in the test/exampleproject.vhde file. You can switch between
the entities and architectures in the project overview on the right, you can
interact with the diagram and optionally save your changes back to disk before
you close the application.
Dependencies
VHDE requires the following packages to be installed:
When we started the fellowship, we knew we were going to work on amazing open source projects, by even more amazing maintainers, contributors, and developers alike. Once the repositories/projects we would be working on were shown, one question really lingered in the air.
How Open Source Friendly is this repo really?
We can always turn to majors repos like React, Vue, Flask, etc. But these don’t paint a picture on what less popular yet still quite active open source projects look like (from a codebase perspective). This idea clicked even further when we were going through the quite frankly simple yet effective LMS Platform for the first week, which consisted of literally, what makes a repo a good open source repo/project.
So putting two and two together, RepoRankr was born!
What it does
RepoRankr‘s main feature is to scan any GitHub Repository and determine a Grade score for how well said repo conforms to best practices of Open Source.
Such as (but not limited to):
Number of Contributors
Most Recent Pull Requests and Issues Dates (both opened and closed)
Issue and Pull Request Templates
Number of topics
Checks for homepage URL, short description and repo name
License verification (More open licenses are favoured)
How we built it
The app infrastructure was quite straightforward, we use Next.js as our React Framework of choice, so we can easily deploy to Vercel. GraphQL calls are made using Apollo Client, and REST calls via Axios.
We leveraged StyleX to style our components and landing page, while it wasn’t out-of-the-norm, per say, we still ran into a few unfavourable challenges.
We utilise the raw power of the GitHub GraphQL API (as well as the REST equivalent for a tiny call), in order to scan the repo, we then format the returned data into a more ‘friendly’ model, pass that through our rank determination algorithm and Bob’s your uncle, the client website will get a grade score, as well as a rundown on some of the checks.
Challenges we ran into
1. Time Zone Challenges
Since each member is quite literally, scattered around the world, our time-zones are not very compatible. We did find a good compromise for a daily standup time (08:00 EST), but we ran into situations where after the standup’s over, the majority of the team would be asleep, leaving 1 or 2 developers contributing alone, and finding it hard to sync up until the next standup.
2. StyleX Problems
Overall we found the development process using stylex quite abnormal compared to just using css modules from next.js, especially with patterns such as copy pasting with the chrome debugger, and nesting and css selectors.
In general, would we use styleX as our css alternative of choice in the future? Problably not.
Did we learn a thing or two about how stylex transforms regular css-in-js into utility classes? Yup!
Accomplishments that we’re proud of
Super proud on the API flow we developed, and understanding the GitHub APIs.
What we learned
CSS-in-JS in practice
More refinement in GraphQL knowledge
Working as an async team with members all over the world
What’s next for RepoRankr
Improve analysis results
More detailed badges
Actually make our own repository more Open Source Friendly
Below are various additional experimental mechanics present here that have been added to supplement Plover theory.
#
# denotes proper nouns (and other parts of speech) and initialisms. It is usually added to the first stroke that comprises the word or phrase. Many of the entries that use this mechanic are found in #-proper-nouns.json.
[Potential change] Require the # modifier for each stroke that starts a new word in the proper noun
[Unclear] When to use # for pascal-case proper nouns
E.g., #PHAT ⇒ Matt.
Caveats
Do strokes containing # obey rules for prefix strokes? How should compound words and multiword titles be handled?
Motivation
This addition has been made due to the high incidence of conflicts between proper words in main.json. main.json usually uses asterisks and stroke duplications to denote proper nouns, but the high number of combinations between these two make it difficult to determine what the resulting spelling/formatting will be. It is also uncertain whether the entries for common proper nouns will even exist, as seen through the high number of misstroke entries that counteract redundant stroke duplications in main.json.
^
^ denotes affixes and segments of compound words. ^ and * (to denote prefixes) are added to all strokes that comprise the affix, but # is only added to the first stroke. Many of the entries that use this mechanic are found in ^-affixes.json.
^ alone usually indicates a suffix, e.g., ^HRAOEUBG ⇒ {^}like.
The addition of * usually indicates a prefix, e.g., ^PH*E/^TA* ⇒ meta{^}.
The typical uses of * for variations, conflicts, and chords that use * still apply in some circumstances, e.g., ^WO*RT/^KWREU ⇒ {^}worthy.
* functions as a toggle (i.e., if a stroke that already contains * would need another * added to it, then the stroke should not have a *), e.g., ^ORT ⇒ ortho{^}. (Find single-stroke entries with the regex ^"[^*]+": ".+\{\^\}",$)
The addition of # usually indicates hyphenation, e.g., #^TPRAOE ⇒ {^}-free.
# can still be used for proper words or proper affixes, e.g., #^WEUPBG ⇒ {*-|}{^}Wing.
[Unclear] When to use ^ or # for pascal-case proper nouns
^ is also uncommonly used to indicate the letter A for briefing purposes.
Caveats
It is still necessary to semantically distinguish between affix strokes and other strokes, and to determine which parts of words are affixes.
Since main.json‘s affix strokes do not have additional modifiers, it is possible to discover some of them through typical syllable splitting without first knowing they are affixes (although this falls apart in the case of conflicts, as described below). All ^ affixes are marked, so this is not possible to do with ^.
If a word can be written using an affix stroke, when should an outline that uses typical syllable splitting without affix strokes be considered incorrect?
When should ^ strokes be explicitly added to outlines for full words? Only when the root alone is not a word or changes spelling? When can the ^ strokes really be considered “affixes”? (e.g., TPHUPL/^PAD ⇒ numpad, TUP/^HRET ⇒ tuplet)
The rule of adding modifiers to the first stroke may not neccessarily be consistent in the case of ambiguities and potential conflicts; e.g., {^}alike should be stroked ^A/^HRAOEUBG instead of ^A/HRAOEUBG.
Motivation
This addition has been made due to the high incidence/load of conflicts and the unpredictability that arises whenever ad-libbing an affix stroke in main.json. The high load of conflicts causes main.json to resort to arbitrary phoneme replacements and briefs that are difficult to predict without previous memorization and knowledge of their existence. main.json also uses * to convert some words into affixes and link together segments of compound words, but this may fall short when a conflict that uses * already exists. It is additionally unpredictable whether the affix will be hyphenated or not, and the need for hyphens may vary depending on style.
This is not intended as a complete replacement for the built-in affix strokes, which are at times more convenient and ergonomic, and more easily merged into other strokes.
+
+ currently has no use.
_
_ tentatively denotes symbols and punctuation. Many of the entries that use this mechanic are found in _-symbols-and-text-commands.json.
&
& is used exclusively for entry to/exit from the orthographic spelling system.
Dictionaries
Located in Plover’s AppData directory (where plover.cfg is located). For brevity, @/ is an alias for ./dicts/.
./dicts/py/ contains additional documentation regarding the usage of each Python dictionary.
Dictionary
Desc
@/hidden/user.json
The inner machinations of my mind
@/json/skeletal.json
Brief-like skeletal entries that contain each syllable of the translated word(s)
@/hidden/names.json
Names of people and brands
@/json/software.json
Software phrases and terminology
@/json/math.json
Math terminology
@/json/dragon.json
Dragon terminology and names
@/json/notion.json
Shortcuts for Notion
@/json/latex.json
LaTeX character and symbol sequences TWHR prefix
@/json/rust.json
Idioms and terminology from Rust
@/json/unicode-typography.json
Unicode characters and their relevant spacing/capitalization
Includes IPA symbols
@/json/custom-commands.json
Commands PWH prefix for text deletion. Right-hand side is based on navigation commands
@/json/spacing-and-capitalization.json
Spacing and capitalization commands KPWAO prefix. Adding E removes the space Some right-hand side commands are partially based on navigation commands; upper row is for uppercase, lower row is for lowercase, symmetric keys for both rows is for spacing, other combinations of the rows for miscellaneous things